
Gefahr im Verzug? Die Zukunft mit KI und Machine Learning
Teil 2: Utopie und Dystopie – ein Ausblick auf künftige Entwicklungen
Gastbeitrag von Dirk Liebich

Alles ohne Mensch? Zum gegenwärtigen Zeitpunkt ist natürlich nicht ansatzweise klar, wie unsere digitale Zukunft mit immer intelligenteren Maschinen aussehen wird. Einerseits gibt es extreme Bedenken hinsichtlich der Übernahme durch sogenannte Superintelligents (Roboter), zumal es kaum moralische Kontrollinstanzen gibt. Andererseits besteht eine sehr hohe Wahrscheinlichkeit, dass es der Menschheit mit den neuen Technologien erheblich besser gehen könnte.
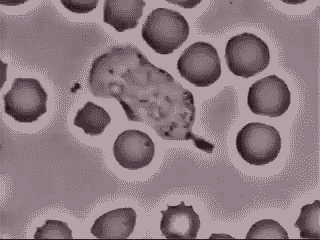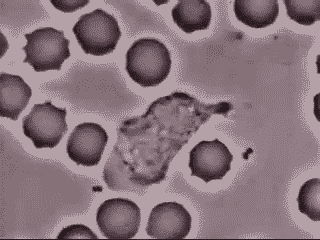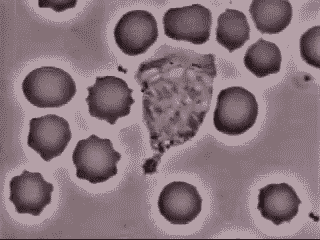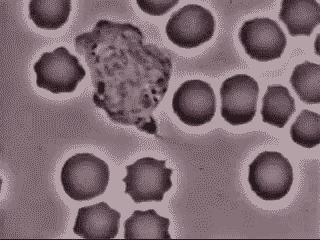
Krankheiten können nicht nur schneller korrigiert werden, der gesamte Bereich der Medizin wird sich vollständig verändern. Wir werden die völlige Personalisierung des Medizinwesens entstehen sehen – DNA-Services as a Service. Auf Basis unseres vollständig entschlüsselten, persönlichen Genoms und mit Hilfe von AI und Machine Learning basierten Modellen werden Organe bei Bedarf entweder repariert oder vollständig ersetzt. Wenn man Vordenkern wie Dr. Ray Kurzweil glauben darf, werden in vielen Bereichen des menschlichen Organismus künstliche Organe und Ersatzmittel (Blut, Sehnen, Knochen) Einzug halten. Unser Blut wird durch nanopartikelbasierte Bots zuerst bereichert und dann ersetzt. Hier ein echtes Beispiel, bei dem ein weißes Blutkörperchen einen Fremdorganismus verfolgt und aufnimmt. So etwas wird in Zukunft durch Nanobots übernommen werden.
Serie KI und Machine Learning
Wie können deutsche Unternehmen doch noch digitale Meister werden? Wie kann man dies mit den Mitteln der Unternehmenskommunikation sowohl anstoßen als auch vorantreiben? Warum brauchen wir eher weniger als mehr Informationen? Wie können Entscheider und Fachleute pragmatische Ansätze entwickeln, die tatsächlich umsetzbar sind? – Dies sind die Fragestellungen meines Themenschwerpunktes Digitalisierung in diesem Herbst hier im PR-Doktor. In der Beschäftigung mit dem Thema habe ich festgestellt, wie viel Nachholbedarf in Sachen Wissen ich selbst noch hatte. Deswegen habe ich einen Machine-Learning-Fachmann gebeten, mir meine brennendsten Fragen zu beantworten. Aus der riesigen Menge an Antworten, Informationen, Beispielen ist diese dreiteilige Serie geworden. – Kerstin Hoffmann
Teil 1: Was Entscheider jetzt über Künstliche Intelligenz und Machine Learning wissen müssen
Teil 2: Gefahr im Verzug? Die Zukunft mit KI und Machine Learning (dieser Beitrag)
Teil 3: KI und Machine Learning in Marketing und Unternehmenskommunikation
All dies wird unter Zuhilfenahme von Künstlicher Intelligenz entwickelt und sicher auch in Teilen gesteuert. Die stark fortschreitende Miniaturisierung von Prozessoren, die immer größer werdenden Mikrospeicher und die schier unerschöpfliche Anzahl von Sensoren: Die Grundlagen entwickeln sich weiter, während dieser Text geschrieben wird.
Das Gehirn des Menschen, unser leistungsstärkstes Werkzeug, wird im ersten Schritt schneller getaktet, in Folgeschritten um eine direkte Anbindung an KI erweitert und letztlich mit Hilfe von DNA basierter BIO-KI auf eine neue Stufe der Leistungsfähigkeit katapultiert. Wir werden nicht nur zu jedem Zeitpunkt auf das gesamte Weltwissen zugreifen können, wir werden dieses auch anwenden können. Ab hier wird es keine Einschränkungen mehr für unsere Entwicklung geben.
Lassen wir eine solche Utopie einmal auf uns wirken, kommen allerdings viele neue Fragen auf, und auf die meisten werden sich, wenn überhaupt, nur schwer und unter großer Anstrengung Antworten finden lassen.
Fragen, die sich daraus ergeben:
- Welche moralischen Grundlagen werden wir etablieren, und werden diese für die gesamte Menschheit gelten oder nur für einige wenige wohlhabende Individuen oder Unternehmen?
- Wie schützen wir uns gegen Missbrauch und Einseitigkeit, Rassismus?
- Wie kann sichergestellt werden, dass die Entwicklungen zum Vorteil der Menschheit genutzt werden, und wer wird dies bewerten?
Von der Utopie zur Dystopie
Leider ist der Mensch nicht immer gut. Zum heutigen Zeitpunkt gibt es immer noch repressive Regimes, und es ist nicht erkennbar, dass sich dies zeitnah ändert. Die neuen Technologien verdrängen entgegen aller Anstrengung Werte wie die Privatsphäre. Im Gegenteil: sie schaffen im Gegensatz Mittel für die vollständige Kontrolle über den Menschen.
Schon heute kann KI-gesteuerte Objekterkennung nicht nur Individuen innerhalb von auch großen Gruppen finden und verfolgen, auch die sich verändernde Gruppendynamik (z.B. bei Versammlungen und Protesten) lässt sich in ersten Modellversuchen bereits vorhersagen. Stellen wir uns einmal diese Auswertungs-, Bewertungs-, und Steuerungsmöglichkeiten in Kombination mit bewaffneten Drohnen vor, so haben wir schnell ein sehr düsteres Szenario.
Aber ein solcher Vorgang wäre ja zumindest nach außen sichtbar und damit könnte der Verbreitung dieser Technologien Widerstand entgegengebracht werden. Viel diffiziler und ungleich potenter sind die Möglichkeiten der impliziten Steuerung über Nachrichten und bekannte Prinzipien wie Aktion und Reaktion: Ich tue etwas – das System belohnt oder bestraft mich. Schon heute wird unser Nachrichtenstrom gezielt manipuliert. Die Ansätze sind bereits im modernen Marketing, der Werbung und Politik erkennbar, sie werden eingesetzt. Hier habe ich bereits vor einiger Zeit gezeigt, wie Bots über moderne Medien Kommunikation schon jetzt manipulieren können.
Von jetzt an ist es nur noch eine Frage der Entwicklungsgeschwindigkeit. Wir gehen noch einen Schritt weiter. Es gibt die ersten Machine-Learning-basierten Modelle für die gezielte Auswertung von menschlichen Gehirnströmen und damit menschlicher Gedanken. Wir denken den Fernseher an und schalten nur mit Hilfe unserer Gedanken zwischen den Programmen um. Vor kurzer Zeit ist es einem MIT-Studenten gelungen ein sogenanntes Silent Interface zum Gehirn zu bauen. Sensoren lesen hier ähnlich dem EEG die Gehirnströme, die während des Denkens von Wörtern entstehen, Machine Learning ordnet den gefundenen Mustern Wörtern zu, ein Folgeprozess führt die erkannten Befehle aus.
Was nun, wenn es Sensoren gäbe, die uns aus der Ferne erfassen könnten? Wir würden nicht nur unsere Privatsphäre verlieren, wir wären jedweder Manipulation von außen schutzlos ausgeliefert.
Sicherheitskonzepte oder die vollständige Abwesenheit derselben!
In allen wichtigen Bereichen unseres Lebens nutzen wir seit jeher Konzepte der Zugangsregelung für den Schutz vor Missbrauch. Software wird ebenfalls auf spezielle Weise geschrieben, um diese vor sogenannten Exploits zu schützen. Es gibt Updates und Fixes, die alle nur die eine Zielsetzung haben, die Anwendung gegen gezielte Fehlnutzung zu sichern.
Im Bereich des Machine Learning gibt es bis zum heutigen Zeitpunkt kein einziges solches Konzept!
Die Notwendigkeit, über Sicherheitskonzepte nachzudenken, ist erst kürzlich klar geworden, nachdem Wissenschaftler aus dem Google Brain Team ein ein trainiertes Objekterkennungsmodell durch gezielte Einbringung von Fehlinformation getäuscht und zu einer Falschaussage bewegt haben. An diesem Beispiel wird sehr deutlich, wie jung der KI-Bereich noch ist.
Da aber fast zeitgleich mit der schnellen Entwicklung auch bereits eine starke Kommerzialisierung einsetzt, ist es dringend notwendig, hier sehr zeitnah nachzubessern und Konzeptarbeit zu leisten.
In der Fortschreibung ist es dann auch nicht unschlüssig zu fragen, ob und welche Sicherheitskonzepte wir in Zukunft für den Schutz unserer Persönlichkeit brauchen, und zwar unserer Persönlichkeit in Form unserer Gedanken, in Kombination mit dem direkten Zugriff darauf. Vielleicht kann dies in einer Fortschreibung der bekannten Virenschutzprogramme bestehen. Die virtuelle und reale Welt werden völlig verschmelzen, und damit wird die Notwendigkeit für eine humanoide Firewall entstehen. Wie sonst sollten wir uns vor ungewolltem Zugriff, Manipulation oder Einflussnahme schützen?
Klar ist: Es gibt weit mehr Fragen als Antworten. Aber selbst diese Fragen sind nur solche, die sich über den angenommenen Kontext bereits erkennen lassen. Die Fragen von morgen kennen wir noch nicht, so wenig wie wir den Entwicklungsstand in neun Monaten von heute vorhersagen können. Vielleicht werden uns Maschinen die Antwort liefern; vielleicht sogar liefern müssen, damit diese und emotions- und wertfrei sind.
„Bias“ und bestürzende Ausreißer
Obwohl große Anstrengungen unternommen werden, neutrale Ergebnisse im Machine Learning zu erstellen, kommt es leider immer wieder zu extrem beunruhigenden Zwischenfällen.
Hier einige von vielen alarmierenden Beispielen (aus den USA):
- Software für die Beurteilung der Rückfallwahrscheinlichkeit von Kriminellen hat ein zweimal so hohes Risiko einer Falschbewertung bei African-Americans als bei Kaukasiern.
- Google Photos kategorisiert African-Americans automatisch als Gorillas. – Hier ein weiterer Link dazu.
- Der Google Übersetzer übersetzt eine initial geschlechterneutrale Aussage aus dem Türkischen in “Er ist Doktor. Sie ist Schwester.”
Warum und wodurch entstehen diese bestürzenden Ausreißer? In der Regel liegt die Ursache in zu wenig oder unzureichend repräsentativen Daten. Der Algorithmus ist nicht rassistisch oder sexistisch. Minderheiten werden oft nicht hinreichend deutlich repräsentiert. Wir erinnern uns: Die Maschine erzeugt die Modelle unserer Welt anhand der zur Verfügung gestellten Daten. Hierbei gilt es zu verstehen, dass Daten niemals neutral sind und auch nicht wirklich neutralisiert werden können. Sie manifestieren unsere Welt, unsere Vergangenheit. Es gilt diese zu verstehen und in die Datenverarbeitung einzubringen. Wer also über die Daten bestimmt, die die Maschine bekommt, kontrolliert letztlich die Ergebnisse und kann damit, wenn man es konsequent zu Ende denkt, auch die wahrgenommene Realität verändern.
Ein weiterer wesentlicher Punkt neben dieser Thematik, von Fachleuten auch als „Bias“ bezeichnet, ist die Frage nach der Präsentation der Ergebnisse gegenüber dem Benutzer. Wenn Informationen nach Wahrscheinlichkeitswerten sortiert und ungeeignet für den Kontext präsentiert werden, besteht die Möglichkeit, dass der Benutzer sein eigenes Wissen und den gesunden Menschenverstand in den Hintergrund stellt. Anstatt die Zusatzinformation wie die zweite Meinung eines Freundes zu hören, wird das Wort der Maschine zum Handlungsgesetz – ein weiterer Aspekt, der in der noch jungen Zukunft der AI zu lösen ist.
Gefahr in Verzug?
Im Folgenden finden Sie einige Beispiele für potentiellen Missbrauch von Machine-Learning-gestützter Überwachung.

- In Zukunft hilft auch die Sonnenbrille nicht gegen das Erkanntwerden.
In diesem englischen Beitrag wird gezeigt wie leistungsfähig die Machine Learning basierte Gesichtserkennung bereits ist. Sogar stark vermummte Gesichter können Personen zugeordnet werden. Der Grund liegt hier im Wesentlichen an der Fähigkeit der Maschine flexibel mit Störinformationen umzugehen.
- Die Maschine weiß, ob du eskalieren wirst.
Grenzgängig gruselig ist dieses Video, in dem Machine Learning basierte Verhaltensanalyse aufgezeigt wird. Hierbei wird die Gruppeninteraktion auf mögliche Auffälligkeiten hin bewertet, Individuen innerhalb der Gruppen dargestellt und identifiziert. Mögliche Eskalationen während einer Demonstration könnten hiermit zum Beispiel vorhergesagt und Gegenmaßnahmen automatisch eingeleitet werden.
- Die Maschine sagt dem Staat, wie glaubwürdig du bist.
Unter dem Titel „Planning Outline for the Construction of a Social Credit System“ wurde das folgende Konzept in China publiziert. Im Kern geht es um die Schaffung eines vollautomatischen Bewertungssystems, das aufzeigt wie glaubwürdig (trustscore) ein Bürger ist. _
- Die Mauer ist zurück.
Das Thema ist wieder einmal die Erstellung und Überwachung einer Grenze durch eine Mauer und obwohl diese Mauer genauso wie die Überwachung virtuell ist, entbehrt das Vorgehensmodell nicht weniger an Schrecken.
- Gedankenlesen ist keine Zauberei mehr.
Das direkte Auslesen unserer Gedanken durch Technologie ist Bestandteil der in diesem Artikel beschriebenen Entwicklung. Hirnströme werden über Sensoren gemessen (EEG) und über Machine Learning in Worte oder Aktionen umgesetzt.
Ausblick auf die kommenden Entwicklungen
Maschinen als Programmierer-Ersatz
Googles CEO Sundar Pichai verkündete im Juli 2018 ein neues Produkt im Bereich des Machine Learnings, mit dem Namen AutoML. Das völlig Neue hierbei ist, dass die Maschine in die Lage versetzt wird, die Arbeit des bis jetzt notwendigen Data Scientist zu übernehmen. Sie kann also gewissermaßen auch noch das Programmieren von Modellen erledigen. Damit wäre die Maschine theoretisch in der Lage, sich selbst um neue Fähigkeiten zu erweitern.
Das klingt zunächst schon ein wenig gruselig, ist bei genauem Hinsehen aber doch zunächst mehr Wunsch als Realität. Das simple Ziel ist die fehlenden Machine-Learning-Programmierer genannt, durch Computerkapazität zu ersetzen.
Evolutionäres Lernen
Ein wenig realistischer ist da ein anderes Vorgehensmodell mit dem Namen Evolutionary Learning: ein Modell, das sich die Evolution zum Beispiel genommen hat und sehr vielversprechende Ergebnisse liefert. Im Kern geht es darum, dem Modell zum Zeitpunkt des Lernens über geeignete Rückkopplung Anreize zur Verbesserung mitzugeben.
Diese Vorgehensweise ist eine Alternative zum sogenannten Reinforcement Learning, ein bekanntes Verfahren, das die Kopplung zwischen Ausgangssignal und Eingangssignal herstellt. Klingt und ist ziemlich komplex, bedeutet aber im Klartext nichts anderes als dass wir wieder einmal bei der Natur abschauen in der Hoffnung, dass nach genügend Versuchen schon ein brauchbares Ergebnis herauskommen wird. Der Unterschied ist, nun können sechs Millionen Jahre der menschlichen Entwicklung innerhalb einiger Wochen oder Monate simuliert werden können.
Gesellschaftliche Auswirkungen der Künstlichen Intelligenz
Von wesentlicherer Bedeutung mit Blick auf die Zukunft dürften aber eher Fragen sein die sich mit den gesellschaftlichen Auswirkungen von KI/AI beschäftigen: vor allem Fragen um die zu erwartenden Veränderungen am Arbeitsplatz, und wie man geeignet und sozial mit diesen Veränderungen umgeht. Auch gibt es – wie oben bereits angesprochen – bereits eine ganze Reihe von moralischen Gesichtspunkten, welche noch viel stärker Betrachtung finden müssen.
Es gibt bereits erste Ansätze, wie das vor kurzem erfolgte Versprechen von AI-Schmieden ihre Kenntnisse nicht zum Unwohl der Menschheit einzusetzen. Wirkliche Kontrollinstanzen, über solche freiwilligen Selbstverpflichtungen hinaus, gibt es jedoch bisher nicht. Hier besteht aus meiner Sicht dringender Handlungsbedarf. Dazu gehört auch, das Wissen um die neuen Technologien für alle verfügbar zu machen. Momentan verfügt nur eine relativ kleine Gruppe von Menschen über diese Technologien, und deren Vorsprung wird immer größer. Eine breite Öffentlichkeit setzt sich mit dem Thema kaum auseinander und ist sich der Auswirkungen nicht bewusst. Dies sollte sich dringend ändern!
 Dirk Liebich arbeitet und berät seit vielen Jahren im internationalen Technologieumfeld direkt an den Quellen der disruptiven Veränderungen in San Francisco, New York und Berlin sowie in Fernost. Seine Spezialgebiete sind Machine Learning, Data Mining und Business Intelligence. Er begleitet Unternehmen in der digitalen Transformation und hilft ihnen, Prozesse, Strukturen und Führung neu zu gestalten, um in einem sich schnell verändernden Umfeld wettbewerbsfähig zu bleiben. Dirk Liebich bloggt, publiziert und hält weltweit Vorträge in englischer und deutscher Sprache.
Dirk Liebich arbeitet und berät seit vielen Jahren im internationalen Technologieumfeld direkt an den Quellen der disruptiven Veränderungen in San Francisco, New York und Berlin sowie in Fernost. Seine Spezialgebiete sind Machine Learning, Data Mining und Business Intelligence. Er begleitet Unternehmen in der digitalen Transformation und hilft ihnen, Prozesse, Strukturen und Führung neu zu gestalten, um in einem sich schnell verändernden Umfeld wettbewerbsfähig zu bleiben. Dirk Liebich bloggt, publiziert und hält weltweit Vorträge in englischer und deutscher Sprache.
– Website
– Flipboard
– Twitter

Schön, dass Sie hier mitlesen. Ich bin Kerstin Hoffmann. Seit vielen Jahren berate und begleite ich Unternehmen in ihrer Kommunikationsstrategie und im Content-Marketing. Besonders spezialisiert bin ich zudem auf Corporate-Influencer-Strategien. Ich halte Vorträge und schreibe Bücher. Lange habe ich an der Heinrich-Heine-Universität Düsseldorf gelehrt, bis heute gebe ich Gastvorlesungen an verschiedenen Hochschulen.
→ Erfahren Sie mehr über das Beratungs- und Vortragsangebot.
Nehmen Sie Kontakt auf:
anfrage@kerstin-hoffmann.de
Kontaktformular


{kind=link}
Kommentare sind deaktiviert.